![]()
|
Valkuilen bij het wisselen van codetabellen
|
Unicode: het universele tekencodeersysteem
|
Bestanden, bestandsnamen en mappen bevatten tekens. Maar de computer slaat ze op als enen en nullen. Voor de vertaling van binaire getallen naar leesbare tekens zijn honderden tekencodeersystemen in gebruik. Hoe vindt u uw teksten terug?
Gebruikt u slechts één besturingssysteem, één bestandssysteem, één toetsenbord, één tekstverwerker en leest en schrijft u slechts berichten in één taal, dan kunt u het bij deze kennis laten. Dikke kans dat u de West Europese Windows codetabellen gebruikt. Maar als uw op de computer aangemaakte geschriften en databases wel eens een landsgrens of een besturingssysteem overbruggen moeten, kan wat achtergrondinformatie geen kwaad.
![]()
|
Bijzondere tekens invoeren |
Zo plaats ik het euroteken (€) onder OS/2 met de rechter Alt-e. Dit werkt zelfs op de prompt. In WordPro werkt Alt-i. Het gaat om de rechter Alt grabbertoets. De linker Alt toets wordt door de menu's gebruikt. Oudere tekstverwerkers kennen de optie om speciale tekens via de Alt grabbertoets gevolgd door met hun decimale ASCII nummer in te voeren. In HTML kan ik het euroteken als € schrijven. StarOffice heeft een menu optie Invoegen /Speciale tekens. WordPro en andere SmartSuite applicaties hebben de optie Symbolen invoegen (Tekst /Overig /Symbool). Andere presentation Manager applicaties kunnen gebruik maken van het klembord in combinatie met Characters Map/2 (charmap114.zip). En zo zijn er wel meer trucjes. Bijvoorbeeld het gebruik van de dode toetsen van het formeel niet door OS/2 ondersteunde Internationale US (lees Windows winkey) toetsenbord. Hiermee kunt u in combinatie met de rechter alt-grabber toets bijzondere tekens samen stellen door bijv. eerst op de Alt-' te tikken en daarna op de e (geeft é). Zie: M.C. de Geus - Accenten in OS/2. Maar met de alt-" en i (ï) werkt dit bij mij niet. |
|
Digitale stroomtreintjes |
Computers werken echter met digitale getallen. Uw teksten worden als getallen versleuteld en verwerkt. De symbolen die op het toetsenbord tikt worden als reeksen van nullen en enen (stroompjes) verwerkt en opgeslagen. Er staan dus geen letters en cijfers op de vaste schijf, maar al dan niet gemagnetiseerde vakjes die op een draaiende schijf reeksen digitale stroompjes genereren. De pulserende stroompjes worden door de hardware als binaire getallen herkend en door het besturingssysteem en de applicaties naar zinvolle tekens vertaald. |
|
Tekencodeer-systemen |
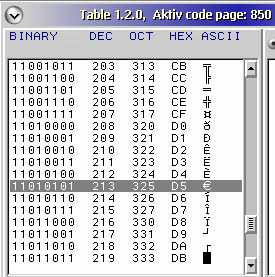
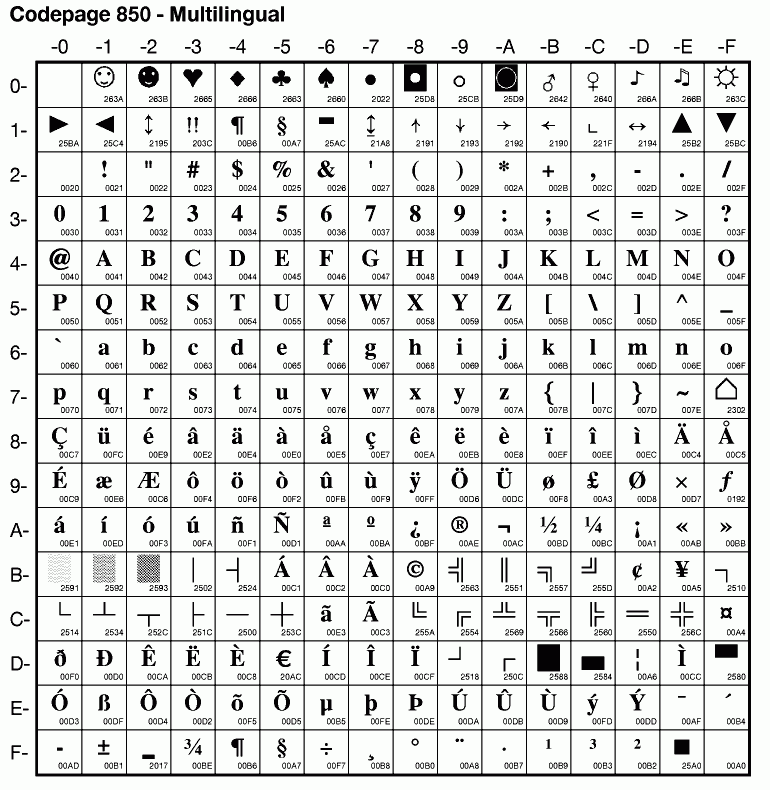
In het kort komt het er dus op neer dat de computer ieder teken als een getal opslaat. De vertaling komt tot stand via een tekencodeersysteem (character encoding) Zo ziet u in de afbeelding hierboven dat OS/2 onder codetabel 850 het euroteken (het decimale ASCII teken 213, D5 in hex) als het binaire getal 11010101 opslaat. Met een geschikt font krijgt u onder CP 850 het euroteken ook weer van het bestandssysteem terug. |
|
Compatibiliteit? |
De manier waarop uw gegevens binair gecodeerd en gedecodeerd worden is van vitaal belang. Is het Windows ANSI of is het een ISO norm? Ziet u Wingdings of ziet u zinvolle tekst? En hoe zit het als gegevens onder verschillende besturingssystemen deelt? Bijv. Linux, OS/2 en Window op HPFS, FAT, FAT32 en JFS? Ziet u dan ook de dezelfde tekens? Hoe zit het met de compatibiliteit? Dat zijn de centrale vragen die ik me hier stel. |
![]()
|
Tekensets en fonts |
Deze 8 bits tekenset bevat 2 tot de macht 8 is 256 tekens (0-255), waarvan de eerste 32 tekens besturingstekens zijn. De tekens uit de eerste twee rijen zijn dan ook niet zomaar met de tekstverwerker in uw teksten in te voegen. Ze hebben een speciale betekenis. Ze worden als besturingscode door printers en terminals gebruikt. Bijv. om het einde van een alinea aan te duiden. Zo ook het afgebeelde hartje (een glyph). Het hartje (ASCII teken 3) wordt op de vaste schijf als 00000011 opgeslagen. Maar of de 00000011 door ieder programma ook als hartje herkent wordt, is nog maar de vraag. Om te beginnen geeft niet iedere font hetzelfde teken weer. Met Characters Map/2 kunt u zien dat ook het postcript font Arial hier een hartje als glyph toont, maar het Windows @Arial webfont toont een nietszeggend hekje. Daarnaast kan het hartje op een computer met een andere niet met ASCII compatibele tekenset (codepage) op een andere locatie kunnen staan. Om die reden is het belangrijk dat een met een ASCII editor als e.exe aangemaakte liefdesbrief ook door uw geliefde met dezelfde font en tekenset gelezen wordt. Anders ontstaan er geheid misverstanden (#$%!). |
|
Teksten verwerken |
Nu is het een taak van uw tekstverwerker om de teksten correct te interpreteren. Een goede tekstverwerker moet niet alleen de juiste tekens opslaan en weergeven, maar ook de juiste opmaak en het juiste lettertype. Uw lettertypes kunt u niet kwijt als gewone tekst (plain text), maar wel in Rich Text Formaat. |
|
Font en codepage incompatibiliteit |
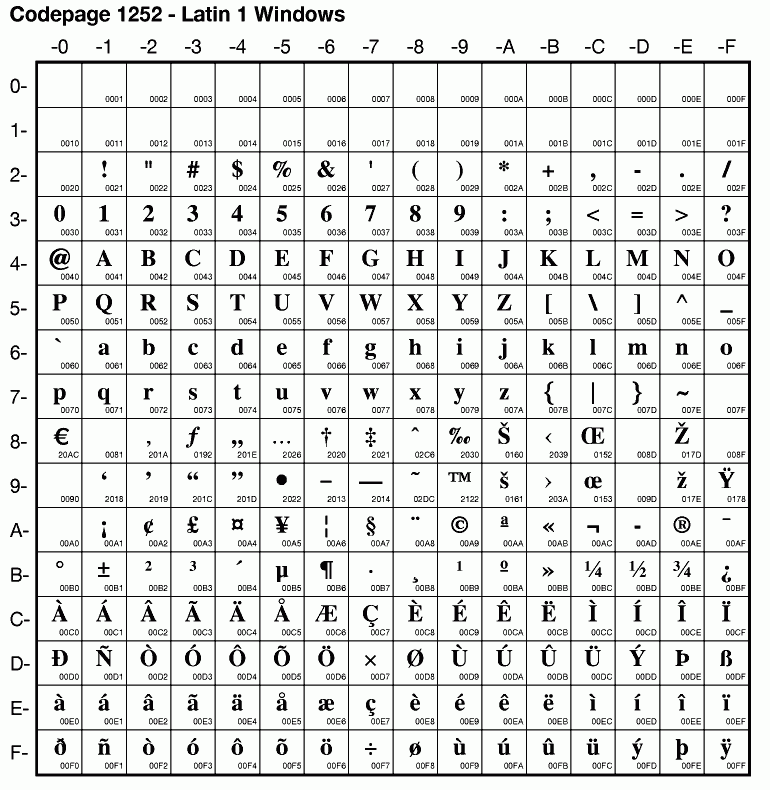
Toch zal de met Postscript Courier geschreven Rich Text Formaat liefdesbrief die ik onder OS/2 schrijf onder de Windows niet goed worden gelezen. Windows gebruikt een andere tekenset (Windows CP 1252 "ANSI" i.p.v. CP 850) en een ander Courier font: De OEM Courier of het TrueType Courier New. U kunt het in Accessories /System Tools/ Character Map bekijken. Weliswaar zullen de meest gebruikte tekens (de getallen en het alfabet) overeenkomen, maar niet alle speciale tekens en zeker niet de grootte en vorm van de fonts. En dan bepaalt de auteur toch niet hoe het overkomt. |
|
Postscript |
Om die reden werd het Postscript formaat populair. Hiermee verstuurt u uw teksten zoals ze worden afgedrukt. Niet alleen in het juiste lettertype, maar ook met de opmaak die daar bij hoort. Maar postscript bestanden zijn groot. Uw mail box zou zo vol zijn. En het verwerken van dergelijke printervriendelijke documenten kost meer processor overhead. |
|
Tekens juist weergeven |
Of het teken dat u aanslaat ook daadwerkelijk weergeven wordt is dus afhankelijk van meerdere factoren.
|
|
Character Table |
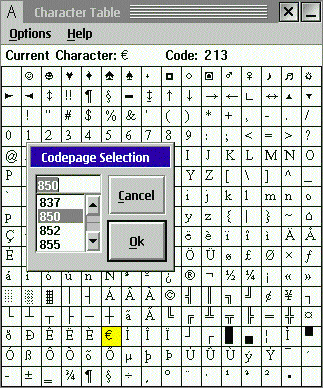
In het voorbeeld hiernaast wordt Times New Roman gebruikt met codepagina 850. Het euroteken krijgt nummer 213. Maar in CP 1004 zal Ascii code 213 op de Õ slaan. De locatie en/of de beschikbaarheid van het euroteken (en andere bijzondere tekens) hangt dus af van de gehanteerde codetabel en de gebruikte fonts. Sommige fonts hebben nauwelijks een uitgebreide tekenset of vertonen Wingdings-achtige fratsen. NB. Onder StarOffice en wordPro en op de prompt geeft Alt-213 superschrift (²¹³) i.p.v. het euroteken. |
![]()
|
Codetabellen |
In het voorbeeld hiernaast is een stukje van meertalige codetabel 850 weergeven. U ziet tekens om lijnen te trekken, het euroteken (€) en speciale hoofdlettertekens. Deze tekens worden aan een getal gekoppeld (character mapping). Iedere rij toont de binaire, decimale, octale en hexadecimaal representaties (getallen) van hetzelfde symbool (de glyph). Hoe de symbolen afgebeeld worden, bepaalt het font. Maar wat er inhoudelijk staat wordt bepaald door het tekennummer in de codepage tabel. Wat zijn de belangrijkste codestelsels? |
|
7 bits ASCII |
Het belangrijkste tekenstelsel vormt het 127 tekens en een spatie tellende American Standard Code for Information Interchange (7 bit ASCII encoding). De eerste ASCII versie (1963) kende alleen hoofdletters. De versie uit 1967 beschikt over de symbolen van het latijnse alfabet in gewone letters en in kapitalen, interpunctietekens, de dollar, commerciële tekens (® © @), de cijfers 0-9 en een reeks besturingstekens die door programma's kunnen worden gebruikt. Het achtste bit werd in terminal sessies wel als parity bit gebruikt. |
|
ISO-646 |
Het 7 bits ASCII was voor de Amerikaanse zakelijke markt ontworpen. Al spoedig kwamen 7-bits West Europese ISO-646 varianten waar op de plaats van zogenaamde variabele (niet essentieel geachte) ASCII tekens ( # $ @ [ ] \ ^ ` { } ~|) gangbare tekens uit andere landen kwamen te staan. Maar vanwege het beperkte aantal tekens voldeden ze voor veel talen maar matig. |
|
IBM's EBCDIC |
Het 8 bits Extended Binary Coded Decimal Interchange Code (EBCDIC) was een uitbreiding van het 6 bits Binary Coded Decimal Interchange Code (BCDIC). ASCII en ISO 646 waren de standaard, maar IBM zette vanaf 1964 op grote schaal haar EBCDIC tekencodes op IBM servers in. IBM ontwierp 57 nationale tekensets voor EBCDIC en een op ISO 646 gebaseerde International Reference Version (IRV), maar de meeste nationale tekensets bleken niet ASCII compatibel en te slecht gedocumenteerd om ze buiten IBM systemen om te gebruiken (foldoc). Ze werden ook niet door DOS of VIO OS/2 applicaties ondersteund. In dit geval fungeerde een Original Equipment Manufacturer (OEM) tekenset als een val voor klanten die hun data gevangen zagen in IBM's wijze van coderen. Later herhaalde Microsoft die "lockup" truc met aparte Windows 3.0 "ANSI" codetabellen die niet met DOS of OS/2 compatibel waren. |
|
PC-8, de Extended ASCII codepages van DOS en OS/2 |
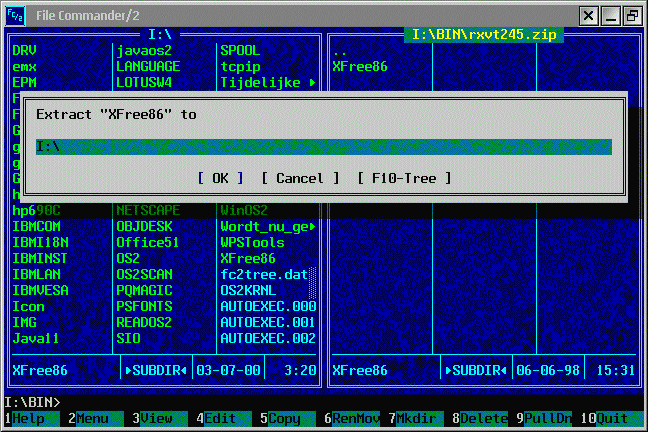
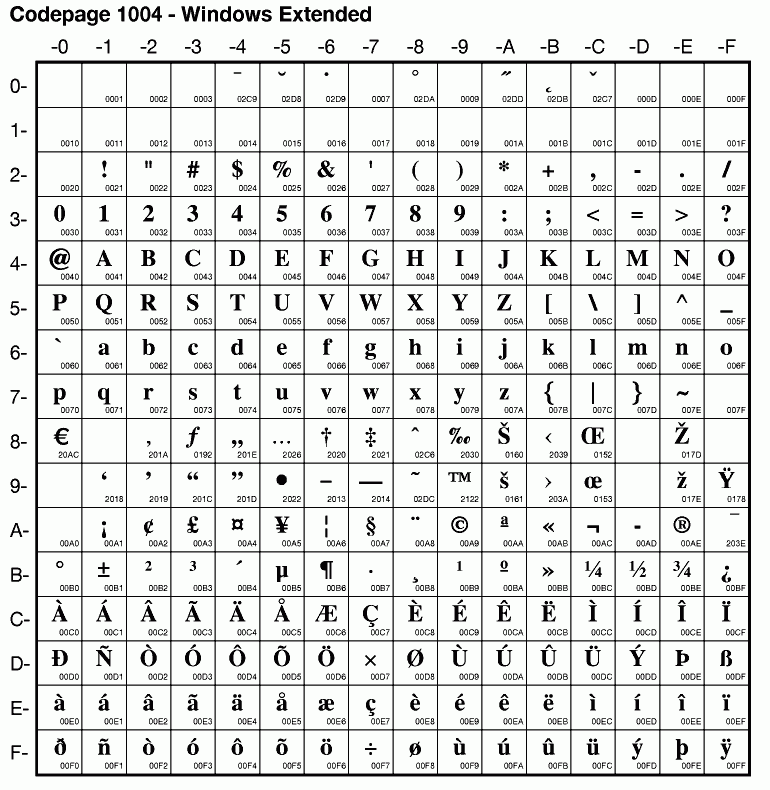
Met de 8 bits Extended ASCII tekenset van de IBM PC® verdubbelde het aantal tekens. In het "8 bits ASCII" behielden de 128 tekens van het 7 bits ASCII hun relatieve positie. Het veranderen van een kleine in een grote letter vereiste dezelfde rekensom: 32 bij de codepoint optellen (schrijven is rekenen voor de PC). Belangrijke toevoegingen aan het 256 tekens tellende PC-8 (CodePage 437) waren tekens om lijnen en eenvoudige grafieken te trekken. Hiermee konden in tekstmodus werkende DOS en OS/2 applicaties een grafisch uiterlijk verwerven (Zie: File Commander/2 en ASCII art). De voor weergave benodigde "hardware" oftewel OEM fonts waren in het BIOS ROM van printers, plotters en videokaarten universeel voorhanden. Deze single byte tekenset werd dan ook default van de in tekstmodus lopende DOS en OS/2 besturingssystemen. NB. Het euroteken werd met FixPak 6 in OS/2 Warp 4 geïntroduceerd. Het kwam in CP 850 (Latin1) en 857 (Turks) op de plaats van de i zonder punt te staan (0xD5). Ook DOS applicaties kunnen er gebruik van maken (re-ALT-i). Win-OS/2 kan dit (ongepatcht) weer niet, aangezien Win-OS/2 van het Windows ANSI codepage systeem gebruik maakt. |
|
National Language Support, NLS |
Maar met de 256 tekens van 8 bits ASCII konden ook tekens uit andere landen (£, €, ï, ñ, û) worden ingevoerd. Microsoft en IBM werkten aan een talenondersteuning voor hun besturingssystemen (National Language Support, NLS). Vanaf versie 3.30 bevatte DOS codepage ondersteuning (mskb 60080). Een van de eerste alternatieve codetabellen voor de standaard CP 437 United States bevatte ondersteuning voor veel West Europese talen (CP 850, Latin1) en was in hoge mate met de ISO-8859-1 versie van Latin1 compatibel. |
|
DBCS |
Aziatische talen kregen Double Byte Character Sets (DBCS) die veel meer tekens ondersteunden. Hierbij moesten nog wel vereenvoudigingen worden doorgevoerd aangezien getekende talen als Koreaans, Chinees en Japans uit vele duizenden tekens bestaan. In Azië ontstond een grote markt voor pen computers: de ruimte op een toetsenbord is immers maar beperkt. |
|
ISO-8859 codetabellen |
Eind jaren 80 zette de European Computer Manufacturers Association (ECMA) samen met International Standard Organization (ISO) 8 bits tekenset coderingen op. Een bekend voorbeeld is ISO-8859-1 die de tekens van de West Europese en Scandinavische talen bevat (CP 819, Latin 1). De kracht van de ISO-8859 reeks is dat zij ruimte voor variatie biedt, maar tegelijkertijd de uitwisselbaarheid met andere talen en tekensetsystemen zo veel mogelijk intact houdt. Zo komen de eerste 128 tekens overeen met 7 bits ASCII. En krijgen speciale tekens die in meerdere ISO-8859 varianten voorkomen dezelfde positie. Vanwege die eigenschappen werd de ISO-8859 tekencoderingswijze de standaard van het internet. |
|
Windows 3.0 ANSI codetabellen |
Microsoft gebruikt vanaf Windows 3.0 verschillende codetabellen onder DOS en Windows. De landsinstellingen van DOS komen steeds overeen met die van OS/2. In de lijst van Localized Microsoft Operating Systems ziet u dat de OEM (lees DOS en OS/2) codetabellen met de OS/2 Locales and Codepages overeenkomen. Recente Window versies ondersteunen tevens de op het internet gangbare ISO-8859 codetabellen. (Zie: Code Pages). Maar veel Windows applicaties maken nog gebruik van de in Windows 3.0 geïntroduceerde "Windows ANSI" codetabellen. Deze codetabellen maken deel uit van de Windows API en kunnen niet door DOS of OS/2 worden geladen. Een voorbeeld is de Windows versie van Latin 1: CP 1252. Grafische GUI's als OS/2's Presentation Manager, Amiga OS and Acorns Archimedes RISC-OS kunnen er wel mee overweg, maar niet de DOS en OS/2 VIO applicaties die van de legacy "OEM" codetabellen gebruik maken. Codetabellen die er op lijken zijn ISO 8859-1 (Latin 1) CP 819 voor PM en CP 1004 Windows Extended voor OS/2 VIO applicaties. Maar het gebruik van CP 1004 kan OS/2 weer in de problemen brengen (zie verder). Windows NT, 2000 en XP maken intern gebruik van Unicode vertalingen (Locales & Languages/Windows Setup Information). |
|
Codetabellen van OS/2 |
Een handig overzicht van de door OS/2 gebruikte codetabellen vindt u bij Ken Borgendale: OS/2 codepages by category. Hij maakt onderscheid tussen de volgende codetabellen: OS/2 Process Codepages: Codetabellen die door alle OS/2 processen (incl. cmd.exe) gebruikt kunnen worden. De bekendsten zijn CP 437 en CP 850. Ze komen overeen met de Windows OEM codepages. ISO 8859 Codepages: Codetabellen zoals gedefinieerd door de International Organization for Standardization. Een deel van de ISO 8859 codetabellen kan door Presentation Manager programma's worden gebruikt (bijv. CP 819). Een ander deel slechts door programma's die de Unicode API ondersteunen (browsers, Java). Windows Codepages: Door Microsoft gedefinieerde codetabellen voor de Windows GUI. Ze kunnen niet door DOS of OS/2 gebruikt worden, maar meestal wel door Presentation Manager. Ze komen overeen met de Windows ANSI (GUI) codetabellen van Microsoft in Code Pages Supported by Windows. ULS converters: Deze groep bevat codetabellen van APL (een programmeertaal), HP en Apple. Ze zijn niet beschikbaar voor OS/2 of PM, maar kunnen via het Universal Language System (ULS, Unicode API) naar door OS/2 ondersteunde tekensets worden omgezet. EBCDIC codepages available from PM: Extended Binary Coded Decimal Interchange (EBCDIC) codetabellen die door Presentation Manager kunnen worden gebruikt. EBCDIC is een IBM server codepage systeem. Other EBCDIC codepages: Extended Binary Coded Decimal Interchange (EBCDIC) codetabellen die niet door Presentation Manager gebruikt kunnen worden, maar wel als ULS converters. |
|
So what? |
Nu denkt u misschien: Leuk om te weten, maar wat die ik ermee? Om het wat concreter te maken geef ik wat voorbeelden uit mijn praktijk. Maar eerst wat uitleg over het begrip "Locale". |
![]()
|
Locale |
Het begrip locale slaat niet alleen op de landstaal en bijbehorende tekens, maar ook op andere regionale gebruiken. Bijvoorbeeld de manier waarop de datum, de tijd, lengtematen, munteenheden en getallen geschreven worden. Zo schrijven Nederlanders 30-04-1948 voor de geboortedag van prinses Juliana. Amerikanen schrijven haar echter als 04/30/1948. Ook "alfabetische" sorteerregels zijn lokaal bepaald. Omdat in Spanje CH een medeklinker is geldt "C,CH,D" als een correcte sorteervolgorde. Maar in Nederland doen we dat weer niet. Ook de sorteerregels van diakritische tekens verschillen per locale. In het Hebreeuws leest men van rechts naar links en Japanners schrijven zowel horizontaal en verticaal. Er zijn zoveel mogelijkheden dat iedere programmeur snel het overzicht zal verliezen. Daarom worden de taalkwesties aan speciale bibliotheken uitbesteed. Meestal worden de lokale formaten door een systeembibliotheek (API) van het besturingssysteem verzorgd. Maar grote databases kunnen hun eigen API's en tekensets hanteren. De gekozen Locale staat in principe los van de taal waarin het besturingssysteem zijn uitgevoerd. Zo werk ik nu op een Amerikaanse versie van eComStation met een voor Nederland ingestelde locale. Zie: Landinstellingen van OS/2. Klassiek is de National Language Support (NLS) API van MS DOS en OS/2. Bij OS/2 Warp 4 met zijn vele subsystemen is de landsondersteuning in een op Unicode gebaseerde Universal Language System (ULS) API ondergebracht. Programma's kunnen de NLS of ULS bibliotheken aanroepen om de gangbare tekens en formaten in te stellen. Maar lang niet alle programma's maken er gebruik van. En dan ziet u toch weer 04/30/1948 als datum staan. |
|
Het belang van een gedocumenteerde locale |
Uit de verscheidenheid van lokale noteer- en en sorteerwijzen mag het belang van een correct ingestelde locale wel duidelijk zijn. Maar wat als u noodgedwongen meerdere locale taalsystemen door elkaar gebruikt? Of verschillende implementaties daarvan? Bijv. wisselt tussen Windows ANSI CP 1252 en de CP 850 van DOS en OS/2? Het gaat in beide gevallen om een Latin 1 tekenset, maar ze worden anders geïmplementeerd. Stel u maakt onder CP 850 een door komma's gescheiden ASCII bestand aan van namen en geboortedata. Daniël,15-04-1992 André,22-2-2001 Inès,3-3-95 Het DOS programma DiskEditor laat de tekens en de codepunten in hex onder CP 850 zien zien.
Daarna maakt u in Lotus Approach een nieuwe database aan met twee velden: naam en datum. Bestand/ Nieuwe database / Blanco database. Voer een naam in en geef de veldnamen en veldtypes op: "naam" als tekst en "geboortedatum" als datum. Nu bent u er nog niet. Ga naar Bestand / Gebruikersinstellingen / Approach voorkeuren. Hier komt in een tabblad aan. Ga naar Database en kies daar de tekenset die u in de database gebruiken wilt: Windows ANSI of DOS of OS/2 (PC-8). In dit geval kies ik voor de opslag van gegevens in Windows ANSI formaat om problemen met Windows te voorkomen. Maar als u veel met DOS of OS/2 databases en spreadsheets werkt die geen Windows ANSI DBF bestanden kunnen lezen of importeren zal de DOS of OS/2 (PC-8) tekenset de betere keus zijn. Door op Default te klikken maakt u de gekozen tekenset instelling als uitgangspunt voor nieuwe databases.
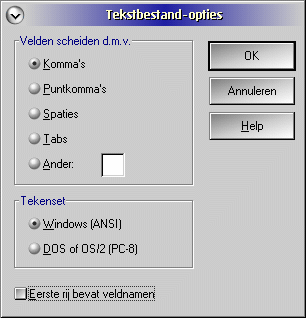
Bestand / Gegevens importeren / selecteer als bestandstype: "Tekst - Met scheidingstekens *.TXT". Er verschijnt een dialoogvenster Tekstbestand-opties: Kies komma's als scheidingsteken. Vink "Eerste rij bevat veldnamen" uit. Welke tekenset u bij de import gebruikt hangt af van de Approach voorkeuren. Als deze dezelfde is als die van de database worden de namen en de in verschillende Nederlandse formaten opgestelde geboortedata correct herkend.
Maar gaat de database uit van PC-8 en importeert u als ANSI dan ziet u dit: DaniÙl,15-04-1992 AndrÚ,22-2-2001 InÞs,3-3-95
Uw neef in Verenigde Staten van Amerika (CP 437) komt ongetwijfeld nog meer in de problemen. In het bestand was immers geen codetabel informatie opgeslagen. Door de andere invoerwijze van de datums in de V.S. zullen ook de geboortedata in de soep lopen. |
|
Codetabellen en de integriteit van uw data |
De integriteit van uw data is met iedere wisseling van codetabel in het geding. Door de lockup in niet universele codetabellen, legacy systems als PC-8 / DOS OEM, Windows ANSI en EBCDIC, te verbreken riskeert u dataverlies. Een bestand in de ene tabel (CP 850) coderen en opslaan en klakkeloos lezen en decoderen in een andere tabel (CP 1252) is vragen om problemen. Onder DOS en Windows was meertaligheid, zowel qua locale als de besturingssysteem specifieke implementatie (API) van de locale, een regelrechte ramp. Lotus Approach vraagt u daarom in de "Tekstbestand opties" met welke tekenset u de data wilt importeren. Is het de Windows ANSI (CP ) of DOS of OS/2 (PC-8) tekenset? Want helaas, dat maakt veel uit. OS/2's CP 850 Latin 1 is niet volledig met de Windows ANSI Latin1 CP 1252 compatibel. Het gaat niet mis als u alleen van ASCII tekens gebruik maakt. Maar als u HTML onder verschillende besturingssystemen met StarOffice schrijft kunt u met niet-ASCII tekens (codepunten > 127) beslist in de problemen komen. Gewoon omdat de standaard (vaak legacy) codetabellen en fonts per besturingssysteem verschillen. Veel bedrijven lossen dit op door zich helemaal aan Microsofts "ANSI" standaarden en software (Office) te houden. Dat kost wel geld, maar ze kunnen de kosten aan hun klanten doorberekenen.
Ernstiger zijn de (soms ontoelaatbare) veranderingen in het bestandssysteem die door codepage wisselingen kunnen ontstaan. Zo kunnen door codetabel wijzigingen buiten de OS/2 API om onleesbare mappen ontstaan. Bijv. als u een bestandssysteem onder meerdere besturingssystemen benadert. Denk hierbij aan een niet unicode API conform netwerk of het gebruik van verschillende stuurbestanden op hetzelfde bestandssysteem. Op die manier kunnen bij backups en restores zeer veel gegevens verloren gaan. |
|
Consequenties voor het bestandssysteem |
Dat een bestand er onder een andere codetabel anders uitziet is de reden dat HPFS de codetabelinformatie met het bestand opslaat. Anders zou u toch wat anders kunnen lezen onder de HPFS stuurbestanden van OS/2 (HPFS.IFS) en Windows NT (PINBALL.SYS). Een server bestandssysteem kan zich zoiets niet permitteren. Maar doordat verschillende besturingssystemen het bestandssysteem anders zullen benaderen kunnen toch ontoelaatbare bestands- en directorynamen ontstaan, waardoor hele stukken in de directorystructuur niet meer te benaderen zijn. HPFS heeft een hoge mate van fouttolerantie. Het kan dus zijn dat u er pas bij een backup van alle bestanden achter komt. Ik zag dit o.a. na het read/write benaderen van HPFS onder Linux. OS/2, Windows NT en opvolgers beschikken over mechanismen om codetabellen "on the fly" te vertalen in de actieve tekenset. Ook Linux kan dit. Maar helaas is het met (Microsofts) HPFS en NTFS documentatie slecht gesteld, zodat het vrijwel onmogelijk is om er betrouwbare open source stuurbestanden voor te maken. Onder Linux kunnen dus bestandsnamen aangemaakt worden, die OS/2 of NT in de problemen zullen brengen. JFS heeft betere papieren. Het is open source en maakt gebruik van Unicode. |
|
Unicode |
Moderne bestandssystemen als NTFS, Reiser en JFS slaan de bestanden en bestandsnamen in unicode op. Onder het 16 bits Unicode (64k tekens mogelijk!) krijgt ieder teken een uniek getal (Zie: Unicode: het universele tekencodeersysteem). Mijn 8 bits ASCII db.txt zou in het 16 bits unicode van JFS dus twee maal zoveel ruimte moeten innemen. Toch geven OS/2 en Linux maar 48 bytes aan. Unicode is dan ook niet een codetabel, maar meer een intern mechanisme om codetabellen te vertalen. |
![]()
|
De legacy subsystemen van OS/2 |
OS/2 kent verschillende "legacy" subsystemen. Als ik het XFree86 subsysteem en Java buiten beschouwing laat, kom ik tot de volgende taalsystemen.
|
|
OS/2 is een integrerend platform. |
Het bovenstaande lijkt complex. Het is het ook. OS/2 Warp 4 bevatte een verscheidenheid aan subsystemen: 16 en 32 bits OS/2, Presentation Manager, DOS, WIN16, WIN32 en Java. En al die subsystemen brachten hun eigen codetabellen, API's en fonts mee. In feite is het nog complexer omdat u onder OS/2 ook X applicaties draaien kunt. Gelukkig is OS/2 Warp een integrerend platform. Het is ontworpen om taal en API barrières te overbruggen. De ontwikkelaars zijn erin geslaagd om de taalinstellingen van verschillende platforms op een lijn te krijgen via een op Unicode gebaseerd Universal Language Support (ULS) systeem. |
|
Config.sys |
Mijn config.sys bevat (de standaard instellingen zijn geremd) landscodes, een code voor het toetsenbord en een opgaaf van de te laden codetabellen. REM DEVINFO=KBD,US,I:\OS2\KEYBOARD.DCP DEVINFO=KBD,UX,I:\OS2\KEYBOARD.DCP DEVINFO (KeyBoardDriver) stelt het toetsenbord in. In dit geval wordt het internationale US toetsenbord (UX) gebruikt. Het internationale toetsenbord is een gewoon US toetsenbord met OS/2 ondersteuning van dode toetsen. In feite gebruik ik een US Windows 95 toetsenbord met een OS/2 winkey driver voor de niet ondersteunde toetsen (winkey02.zip). De Windows toets wordt gebruikt voor het taakoverzicht. De ingang voor het Amerikaanse (US) toetsenbord is geremd. COUNTRY=031,I:\OS2\SYSTEM\COUNTRY.SYS De COUNTRY= instelling wordt gebruikt door DOS en OS/2 toepassingen die de National Language Support (NLS) API gebruiken. Deze system locale bepaalt o.a. het formaat waarin datums, tijd en getallen worden getoond. Die kunnen per land (locale) verschillen. U kunt een deel ervan in Configuratie onder Locale (Landinstellingen) bijstellen. CODEPAGE=850,437 In West Europa en Scandinavië worden standaard twee codetabellen voorbereid: het West Europese Latin 1 (850) en dat van de Verenigde Staten (437). Ze gelden niet alleen voor de DOS en OS/2 opdrachtverwerkers, maar ook voor andere VIO programma's van het OS/2 besturingssysteem. Het zijn dus echte systeem codetabellen waar u niet zomaar aan kunt morrelen. OS/2 programma's In Nederland is CP 850 actief. Dit komt overeen met de instellingen van de Nederlandse Microsoft DOS opdrachtverwerker: COUNTRY=031,850,C:\WINDOWS\COMMAND\COUNTRY.SYS |
|
Universal Language Support (ULS) |
Deze ingangen hebben betrekking op IBM's Universal Language Support (ULS) systeem. Het voegt Unicode ondersteuning aan OS/2 toe. SET ULSPATH=I:\LANGUAGE SET LOCPATH=I:\IBMI18N\LOCALE;I:\LANGUAGE\LOCALE SET LANG=nl_NL_EURO De bijbehorende SET LANG(uage) instelling geeft de "locale" aan voor programma's die van OS/2's Unicode Locale gebruik maken. Denk hierbij aan Java, databases, servers en browsers. Onder Warp 4 (1996) werd SET LANG=nl_NL gebruikt. |
|
Unicode.sys |
JFS en UDF (eComStation en ) maken gebruik van het stuurbestand UNICODE.SYS om codepages "on the fly" te vertalen. DEVICE=I:\OS2\BOOT\UNICODE.SYS IFS=I:\OS2\JFS.IFS /LW:5,20,4 /AUTOCHECK:* /CACHE:96000 Let op: UNICODE.SYS moet voor JFS.IFS (en UDF.IFS) geladen zijn. |
|
OS/2 Process Codepages |
Het OS/2 besturingssysteem laadt via het stuurbestand COUNTRY.SYS en de setting CODEPAGE=CP1e,CP2e twee tekensets in het geheugen, waarvan er per OS/2 sessie een actief is. Hier is de codetabel 850 (DOS Meertalig, Multilingual Latin I) actief en is de codetabel 437 (US) beschikbaar. [H:\]chcp
In OS/2 Locales and Codepages ziet u een tabel die aangeeft welke codetabellen OS/2 in ieder land (locale) gebruikt. In Nederland en andere landen met het latijnse schrift kan de CONFIG.SYS variabele CODEPAGE=850,437 vervangen worden door: CODEPAGE=850,1004 Met chcp (change codepage) kunt u de actieve tekenset opvragen en wijzigen. Chcp 1004 verandert de in de OS/2 sessie actieve tekenset van 850 in in 1004. Helaas kunnen de in de List of Localized MS Operating Systems vermelde ANSI Windows codetabellen (CP 1252 e.d.) niet met de opdracht CODEPAGE geladen worden. Maar alle zogenaamde OEM (DOS) en ANSI (Windows GDI) codetabellen worden wel door Presentation Manager beschikbaar gesteld. Presentation Manager applicaties kunnen alle codetabellen uit \LANGUAGE\CODEPAGE gebruiken. Maar lang niet alle OS/2 programma's maken bij hun in- en exportfuncties voldoende gebruik van de talen API's. Daarom wordt Windows Latin (CP 1004) wel als tweede OS/2 systeem codetabel gebruikt vanwege de gelijkenis met het in grafische Windows omgevingen gebruikte Latin 1 CP 1252. Het ondersteunt meer Europese lettertekens, maar minder "ASCII art". Vergelijk de voor "ASCII art" ingestelde "OS/2 legacy" CP 850 en CP 437, maar eens met de meer op lettertekens ingestelde Windows "legacy" tabellen CP 1004 en CP 1252 in de tabs van Mozilla.
FC/2 moet u na een chcp 850 of chcp 437 laden voor een grafisch resultaat. En na een modewijziging om uw niet meer EGA beeldscherm beter te benutten. MODE CO80,43 CHCP 850 C: CD \ CD BIN\DISK\FC2_212 FC.EXE Hiermee ziet u weer het Norton Commander achtige beeld. |
|
Legacy systems |
Dit voorbeeld geeft ook mooi aan wat er met een legacy system bedoeld wordt. Ik citeer scherpe definitie van de Free Online Dictionary of Computing (FOLDOC): A computer system or application program which continues to be used because of the cost of replacing or redesigning it and often despite its poor competitiveness and compatibility with modern equivalents. The implication is that the system is large, monolithic and difficult to modify. If legacy software only runs on antiquated hardware the cost of maintaining this may eventually outweigh the cost of replacing both the software and hardware unless some form of emulation or backward compatibility allows the software to run on new hardware. (1998-08-09) In een legacy systeem zijn ontwikkelaars en gebruikers aan allerlei regels gebonden. Zo lopen de DOS en OS/2 processen onder de in het BIOS ingebakken PC-8 tekenset van de OEM en IBM PC's. Dat was voor de eerste versies DOS een noodzaak. Zonder de ondersteuning van dergelijke "hardware font" liep DOS niet. Er was te weinig geheugen en de stuurbestanden om codetabellen te laden ontbraken. Doordat Microsoft later haar eigen, niet met de OS/2 en DOS "legacy" codetabellen (437,850) overeenkomende "ANSI" standaarden (12) introduceerde voor haar grafische besturingssysteem Windows, ontstond er weer een nieuw "bug or feature" incompatibiteitsprobleem. Voor Microsoft bleek deze zet een feature, voor DOS en OS/2 gebruikers een ramp. |
|
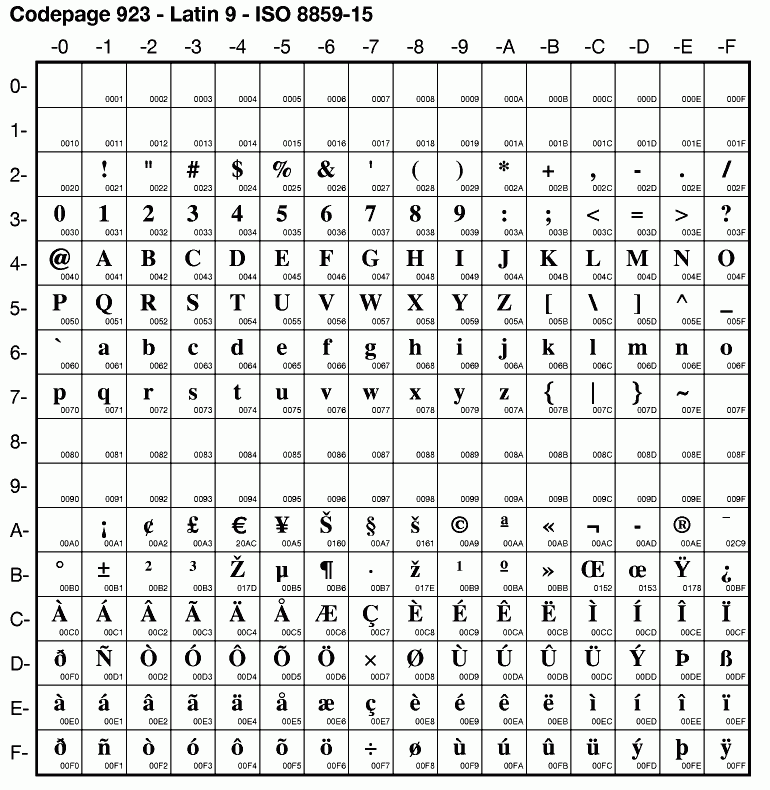
ISO tekensets |
Veel OS/2 internetprogramma's gebruiken Codepage 819 oftwel ISO-8859-1 (Latin 1). Maar deze ondersteunt de euro niet. Codepage 923, ISO 8859-15 (Latin 9) doet dat wel. |
|
Character Table |
In het voorbeeld hiernaast wordt Times New Roman gebruikt met codepagina 850. Het euroteken krijgt nummer 213. Maar in CP 1004 zal Ascii code 213 op de Õ slaan. De locatie en/of de beschikbaarheid van het euroteken (en andere bijzondere tekens) hangt dus af van de gehanteerde codetabel en de gebruikte fonts. Sommige fonts hebben nauwelijks een uitgebreide tekenset of vertonen Wingdings-achtige fratsen. NB. Onder StarOffice en wordPro en op de prompt geeft Alt-213 superschrift (²¹³) i.p.v. het euroteken. |
![]()
|
Unicode/ISO-10646 |
De gedachte om een universele talencode te ontwikkelen is niet nieuw. Marc Davis van Apple en teams van Xerox begonnen er al in 1985 mee. Xerox medewerkers legden de overeenkomsten van het Chinese en Japanse schrift vast in de HAN unification. Na gesprekken met Apple medewerkers lanceerde Joseph Becker van Xerox in 1988 de term Unicode 1 voor een universele tekencodering (character encoding). Er vonden meer gesprekken plaats en in 1991 werd het Unicode/ISO-10646 systeem van het Unicode Consortium geboren waarin de ISO-8859-x standaarden met de Han unification samensmolten. |
|
Wat is Unicode? |
Op http://www.unicode.org zegt Unicode Consortium: Wat is Unicode? : Unicode biedt een uniek getal voor elk teken, ongeacht het gebruikte platform, ongeacht het gebruikte programma, ongeacht de gebruikte taal. Unicode werd een groot succes: Webservers, browsers en databases maken gebruik van Unicode in XML, Java, JavaScript, LDAP, CORBA 3.0, WML om zonder gegevensverlies door taalkwesties informatie uit te wisselen. De kracht van Unicode is dat het niet alleen een systeem voor de vertaling van landstalen is, maar dat Unicode ook in staat is om de eigengereide codepagina's van software fabrikanten (IBM's EBCDIC, Microsofts ANSI) te verbinden. Ondersteuning van Unicode door databases en servers voorkomt daarmee een vendor lockup door taalkwesties. De gegevens blijven uitwisselbaar tussen de verschillende platformen. |
|
De Universal Glyph List (UGL) |
IBM heeft een groot deel van de tekens van de wereld (glyphens) in kaart gebracht. Het resultaat ziet u op de Universal Glyph List (UGL) for OS/2 Warp Server for e-business: Deze universele tekenset combineert Latijnse, PC, Cyrillische, Windows, Apple, Hebreeuwse, Griekse, Arabische, Japanse, Koreaanse and Thaise karakter tekens tot een enkele tekenset. |
|
NLS versus Unicode |
Nu kunnen niet al die tekens op de OS/2 prompt verschijnen. Die maakt immers gebruik van de uit DOS tijden stammende National Language Support (NLS API) die op 8 bit codepages van maximaal 256 tekens is gebaseerd. En hierbij is steeds maar een tekenset actief. Een Unicode codepage voor OS/2 zult u dus niet zien. |
|
Java en Unicode |
Wel bestaat er een zwaar uitgevallen Unicode font voor Java. Java is niet aan OS/2's legacy beperkingen gebonden. Maar het "Write once, run everywhere" zou niet zonder Unicode kunnen bestaan. |
|
Unicode support in OS/2 Warp 4 |
Vanaf OS/2 Warp 4 (1996) bevat OS/2 Unicode support in de vorm van een Unicode bibliotheek (o.a. libuni.dll, uconv.dll) die codepages kan vertalen. De Unicode support maakt deel uit van een breed opgezet Universal Language Support (ULS) systeem. |
|
Universal Language Support (ULS) |
In OS/2 Warp 4 en eComstation is Unicode in IBM's Universal Language Support (ULS) ondergebracht (uls.pdf). De landsondersteuning van software kost veel tijd en geld. Als ontwikkelaars voor landsondersteuning van speciale bibliotheken gebruik kunnen maken, besparen ze ontwikkelings- en onderhoudskosten. Dat was de reden voor IBM om zich op ondersteuning van Universal Language Support te werpen. IBM's Universal Language Support (ULS) is meer dan een poging om alle codepages via Unicode aaneen te rijgen. Het gaat niet alleen om de taal, maar ook om andere regionale gebruiken ("locale"). Bijvoorbeeld de manier waarop de datum, de tijd, lengtematen, munteenheden en getallen geschreven worden. Met het WPS programma Graphical Locale Builder (System Setup/ Locale) kunnen gebruikers zonder te rebooten een hele rits lokale instellingen wijzigen. De instellingen betreffen Java, OS/2 legacy (het oude NLS systeem), de X/Open Portability Guide/4 en Windows. Via Country Palette / Locale / Open as/ New Locale kunt nieuwe voorkeuren aanmaken of wijzigen. Via het tabblad Advanced kunt u dat op maat doen. Met de optie Default stelt u een bepaalde Locale als "User Locale" in. Maar niet alle wijzigingen zullen meteen gelden. En sommige veranderingen in de Advanced Tab beklijven niet. Zo kunt u de variabelen iCodepage en iAltCodepage voor de primaire en secundaire OS/2 proces codetabellen alleen via een reboot kunnen wijzigen. Ze maken deel uit van de Systeem Locale die met CODEPAGE=850,437 in de CONFIG.SYS vastgelegd wordt. Delen van het besturingssysteem en programma's die niet van Unicode gebruik kunnen maken zijn er van afhankelijk. Ga er dus voorzichtig mee om. Een berucht voorbeeld is de Duitse "Arbeitsoberfläche" die vanwege de umlaut niet meer terug gevonden wordt na een codepage verandering. Zie de discussie in Codepage handling bug?. De soortgelijke Nederlandse bron van ellende is de map "DESKTOP\Programma's\Modellen\Lotus Word Pro^SmartMaster-sjablonen\Internet\Internet - Privé". Deze map is op HPFS wel aan te maken, maar wordt als hij van HPFS op JFS gezet wordt en weer teruggezet wordt blijkbaar niet goed vertaald. Want op HPFS ontstaat dan het probleem dat hij niet meer te wissen is:l Directory does not exist, cannot delete DESKTOP\Programma's\Modellen\Lotus Word Pro^SmartMaster-sjablonen\Internet\Internet - Privé Een Robosave of XWorkplace scripts dat de Desktop eerst moet wissen om het daarna te herstellen loopt er op vast. En dan hebt u een groot probleem. |
|
JFS en Unicode |
Ook IBM's Journaled File System maakt gebruik van Unicode omzettingen om opgeslagen data correct weer te geven. |
![]()
|
Meer lezen |
Iemand die u alles over OS/2 Warp Internationalization vertellen kan is Ken Borgendale. Ken heeft ook utilities beschikbaar om codetabellen en toetsenbord layouts te printen (OS/2 Codepage and Keyboard Display Tools). De homepage van Steven Atkin bevat veel achtergrondartikelen. O.a. zijn boeiende dissertatie "A Framework for Multilingual Information Processing" en IBM Graphical Locale Builder door Steve Atkin en Ken Borgendale. |
|
|
OS/2 Warp Internationalization van Ken Borgendale. M.C. de Geus - Accenten in OS/2 Characters and encodings : veel achtergrondinformatie van Jukka Korpela. A brief introduction to code pages and Unicode : op IBM sites staan tientallen artikelen over Unicode. Character sets and codepages : Microsoft over "Preparing for TrueType Open". Zie ook: Fonts en What is the History of TrueType : Microsoft en Adobe zijn niet zo open als ze zich voordoen. List of Localized MS Operating Systems References bevat Code Pages Supported by Windows. Wat is Unicode? : Unicode biedt een uniek getal voor elk teken, ongeacht het gebruikte platform, ongeacht het gebruikte programma, ongeacht de gebruikte taal. |
 Lang
niet alle tekens worden door uw toetsenbord gedekt. Veel
programma's bevatten daarom menu's en sneltoetsen om speciale
tekens in te voeren.
Lang
niet alle tekens worden door uw toetsenbord gedekt. Veel
programma's bevatten daarom menu's en sneltoetsen om speciale
tekens in te voeren.
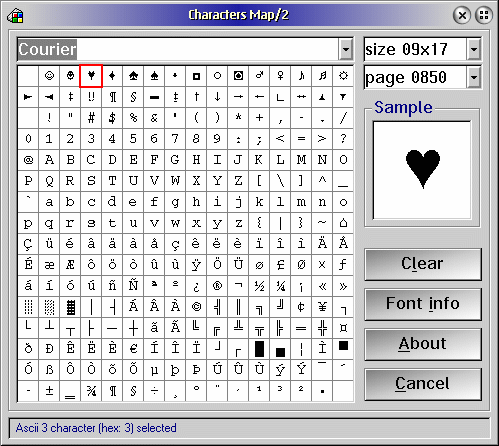 In
het voorbeeld hiernaast zijn de beschikbare tekens (tekenset) van
het postscript font Courier voor Codetabel 850 (Latin 1)
afgebeeld.
In
het voorbeeld hiernaast zijn de beschikbare tekens (tekenset) van
het postscript font Courier voor Codetabel 850 (Latin 1)
afgebeeld.
 Met
het programma Character Table (
Met
het programma Character Table (
 U
importeert de gegevens uit het tekstbestand als volgt:
U
importeert de gegevens uit het tekstbestand als volgt: De
bijzondere tekens in de 2e helft van de Windows ANSI codetabel
worden niet goed onder CP 850 van MS DOS weergeven.
De
bijzondere tekens in de 2e helft van de Windows ANSI codetabel
worden niet goed onder CP 850 van MS DOS weergeven.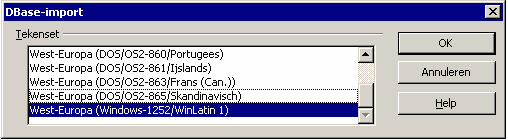
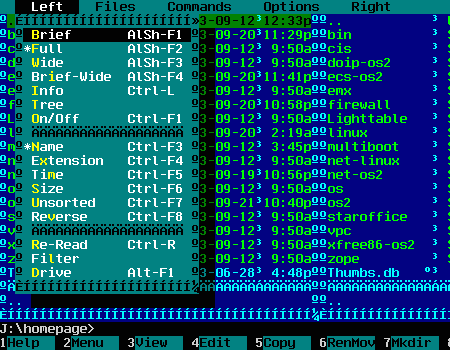 Maar
onder het op Windows ANSI CP 1252 gelijkende CP 1004 zullen
"grafische" VIO applicaties onooglijk lijken: Zie de
treurige aanblik van de in tekstmodus lopende Norton Commander
clone
Maar
onder het op Windows ANSI CP 1252 gelijkende CP 1004 zullen
"grafische" VIO applicaties onooglijk lijken: Zie de
treurige aanblik van de in tekstmodus lopende Norton Commander
clone 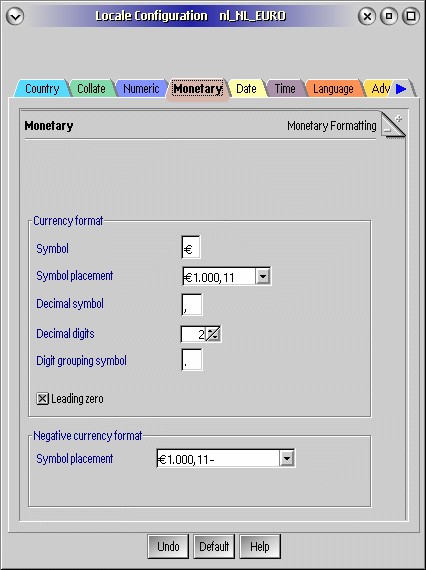 Unicode
is een poging om alle tekensets van de wereld in een
allesomvattend talensysteem te verenigen. Unicode deed zijn
intrede in de servers, maar wordt nu ook door moderne PC
besturingssystemen (Windows 2000 en XP, Linux en in OS/2 al vanaf
1996) ondersteund.
Unicode
is een poging om alle tekensets van de wereld in een
allesomvattend talensysteem te verenigen. Unicode deed zijn
intrede in de servers, maar wordt nu ook door moderne PC
besturingssystemen (Windows 2000 en XP, Linux en in OS/2 al vanaf
1996) ondersteund.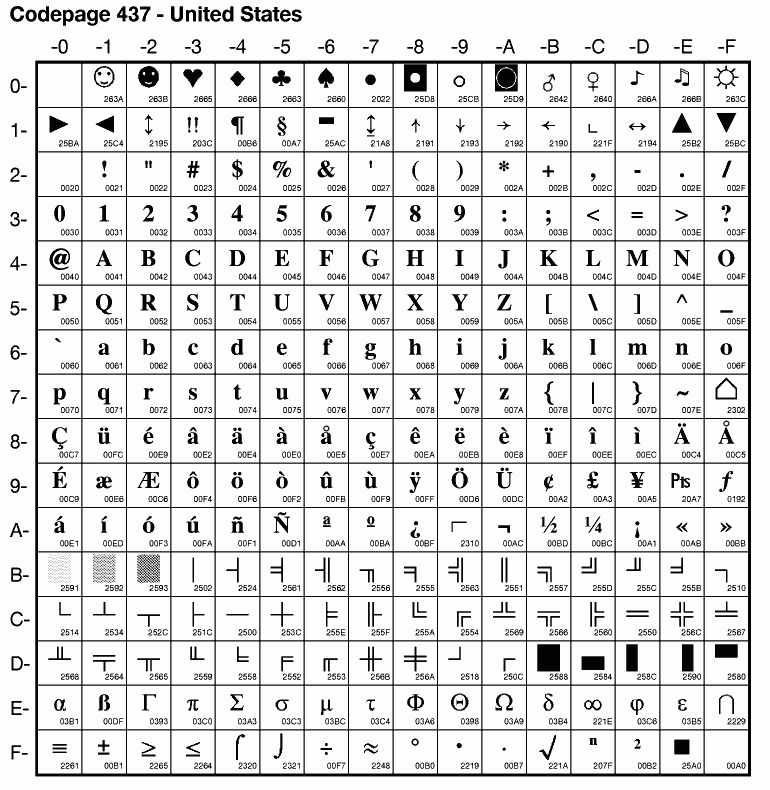{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}